|
|
Item13378: Incorrect rendering utf8 WikiWords in the Form's default text.
Priority: Urgent
Current State: Closed
Released In: 2.0.0
Target Release: major
Current State: Closed
Released In: 2.0.0
Target Release: major
How to reproduce
- setup utf8 Foswiki
- download the formtest.tgz from the Item13331 http://foswiki.org/pub/Tasks/Item13331/formtest.tgz
- untar
- check
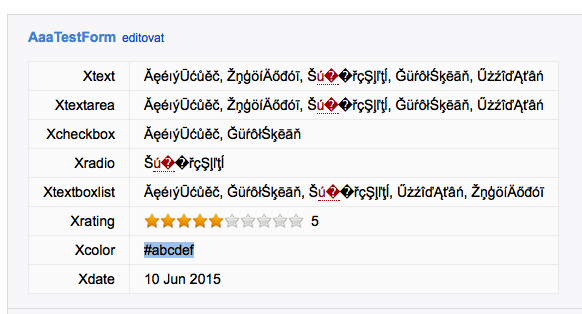
<noautolink>.... or the * Set NOAUTOLINK = 1e.g. Disabling auto linking helps. -- JozefMojzis - 20 Apr 2015 This appears to be an issue in form rendering. The wikiword is detected but only in the textarea and textfield form entries. The word does not link from within the topic text proper. In addition raw view and form editing is working fine. It's only rendering of the form that's broken. Confirmed. -- GeorgeClark - 20 Apr 2015 The form renders as:
<td> ĂęéıýŪćůěč, ŽņģöíÄőđóī, Š<a class="foswikiNewLink" href="/bin/edit/Sandbox/ú�?topicparent=Sandbox.AaaTesting1" rel="nofollow" title="Create this topic">ú�</a>�řçŞļľţĺ, ĞüŕôłŚķēāň, Űżźî諾âń </td>-- GeorgeClark - 20 Apr 2015 added an screenshot -- JozefMojzis - 20 Apr 2015 It seems to be a single character that triggers this, and only in forms ú ends up linking as a wikiword only when in a form or attachment comment. Attach a file, and make the comment only 2 characters úů and the first character ends up linking
- screenshot_63.png:

 Nor does "ŠúářçŞļľţĺ" qualify as a WikiWord (using an utf8 site charset, no locale, no locale'd regexes, perl-5.20.2, CGI-4.15).
See also https://demo.michaeldaumconsulting.com/bin/view/Sandbox/AaaTesting1?skin=pattern
Note that
Nor does "ŠúářçŞļľţĺ" qualify as a WikiWord (using an utf8 site charset, no locale, no locale'd regexes, perl-5.20.2, CGI-4.15).
See also https://demo.michaeldaumconsulting.com/bin/view/Sandbox/AaaTesting1?skin=pattern
Note that {Site}{LocaleRegexes} = 0 ... which seems to make a difference according to Jozef.
-- MichaelDaum - 21 Apr 2015
Ok, exactly what i did:
dir=utest5 mkdir "$dir" cd "$dir" git clone https://github.com/foswiki/distro foswiki cd foswiki/core perl -T ./pseudo-install.pl developer (echo ''; echo 'y') | (cd tools && perl -I ../lib rewriteshebang.pl) tools/lighttpd.plgo to http://localhost:8080 and configured 3 things:
-
{SafeEnvPath}because lighted doesn't provide PATH -
{Password}internal Admin passwd -
{Plugins}{UpdatesPlugin}{ConfigureUrl}because the configure doesn't detects it - Save the config,
- create the web "Jomoutf"
- untar the formtest.tgz
- Show the AaaTesting1 - result screwed characters
- uncheck the
{Site}{LocaleRegexes} - reload the AaaTesting1 - and it shows OK.
tango:core clt$ uname -a Darwin tango.local 14.3.0 Darwin Kernel Version 14.3.0: Mon Mar 23 11:59:05 PDT 2015; root:xnu-2782.20.48~5/RELEASE_X86_64 x86_64 tango:core clt$ perl -v This is perl 5, version 20, subversion 1 (v5.20.1) built for darwin-thread-multi-2level tango:core clt$ perl -MCGI -E 'say $CGI::VERSION' 4.15
- the perl is perlbrew
{Site}{LocaleRegexes} to 0.
-- JozefMojzis - 21 Apr 2015
So, what now? Set this to "No Action needed"? Maybe some warning into installation guide for OS X users - they need disable the default {Site}{LocaleRegexes} checkbox (it is in the Expert Settings). Or... ?
-- JozefMojzis - 21 Apr 2015
No I'll check out bootstrap and the defaults. You really should not have to change this I don't think.
-- GeorgeClark - 21 Apr 2015
I'm not sure I agree with the fix. Disabling LocaleRegexes forces foswiki to hard-code the WikiWord regex to use $regex{upperAlpha} = 'A-Z' , $regex{lowerAlpha} = 'a-z', ... What I don't understand is why the bug only shows up in form and attachment fields, but not in inline text. If it's a WikiWord, it should be matching in either location. So I suspect something different is happening with rendering of the form fields that is causing the regex to match.
-- GeorgeClark - 22 Apr 2015
Crawford found and fixed the issue. Closing.
-- GeorgeClark - 23 Apr 2015
Crawford, your fix distro:4296db11987a broke the fix for this task.
The below stolen from your suggested fix to Fn_LANGUAGES seems to fix it for me.
diff --git a/SubscribePlugin/lib/Foswiki/Plugins/SubscribePlugin.pm b/SubscribePlugin/lib/Foswiki/Plugins/SubscribePlugin.pm
index ec2e0aa..0e66d0a 100644
--- a/SubscribePlugin/lib/Foswiki/Plugins/SubscribePlugin.pm
+++ b/SubscribePlugin/lib/Foswiki/Plugins/SubscribePlugin.pm
@@ -17,6 +17,7 @@ use Assert;
use Error ':try';
use JSON ();
use HTML::Entities ();
+use Encode;
our $VERSION = '3.2';
our $RELEASE = '24 Nov 2014';
@@ -129,6 +130,7 @@ sub _SUBSCRIBE {
# $json is UTF8 - must convert to the site encoding
$json = $Foswiki::Plugins::SESSION->UTF82SiteCharSet($json);
+ $json = Encode::encode( $Foswiki::cfg{Site}{CharSet}, $json, Encode::FB_CROAK );
my $data = HTML::Entities::encode_entities($json);
$tmpl =~ s/\%JSON_DATA\%/$data/g;
-- GeorgeClark - 24 Apr 2015
Jomo confirmed that this fix worked for him too. Part of the issue is that the SiteCharSet is already Utf8, so UTF82SiteCharSet just returns the input data. (Tests, if SiteCharset is already UTF8, no need to convert anything)
I suspect the Encode::encode should be in an eval, so that if there are issues in the text it can be caught rather than die.
-- GeorgeClark - 24 Apr 2015
That's definitely wrong. I've been suspicious of UTF82SiteCharSet for a while now. Will investigate.
-- CrawfordCurrie - 25 Apr 2015
Later: so, this is a can of worms.
CGI returns all params (including path_info, url etc) in UTF-8 encoded byte strings. By happy coincidence, this is how perl internally represents UNICODE, so these strings
appear to be UNICODE to most perl applications. Foswiki, in many places, does not decode these byte strings to the {Site}{CharSet} (topic and web name parameters, attachment
filenames etc etc), However all strings output in the HTML must be output using the {Site}{CharSet}. So long as only 7-bit characters are used,
this is not a problem, but as soon as wide-byte characters are involved, it all falls apart.
There are two approaches to solving this: - Call Foswiki::UTF82SiteCharSet() everywhere a parameter value is destined to end up in HTML output
- Convert all param() etc inside Foswiki::Request so they are decoded to the {Site}{CharSet} before the
->param(call.
{Site}{CharSet} other than utf8. We cannot release the way it is. I have started the process of (1) above, but it looks like there may be a lot of edge cases (e.g. usernames nd passwords; do we support wide byte chars in them?)
-- CrawfordCurrie - 25 Apr 2015
CDot, hm... to be exact - check the lines 441-443 and 449-458 in the https://github.com/leejo/CGI.pm/blob/master/lib/CGI.pm . They could be correctly decoded into perl's "characters" (code points). (correctly mean: with the Encode::decode, not with the hackish utf8:upgrade...) - so, is possible ensure to getting consistent (everywhere) utf8 code point receive from the CGI - only need use the CGI as use CGI qw(:utf8); After this is possible to convert it into the octets what currently Foswiki uses internally. E.g. from the CGI you could get a string what doesn't appears as utf8 encoded byte string, but perl "character-string". (Intentionally using the "character" word). What i mean:
$ perl -MCGI=:utf8 -E '$q=CGI->new();say length($q->param("a"));' a=ž #one character z-caron
1
$ perl -MCGI -E '$q=CGI->new();say length($q->param("a"));' a=ž
2
-- JozefMojzis - 25 Apr 2015
We just have to be careful not to go too far with changes to 1.2, I'm concerned about any impact on the Beta and release process.
-- GeorgeClark - 26 Apr 2015
MichaelDaum appears to have fixed this issue with changes checked in under Item13393.
-- GeorgeClark - 04 May 2015
Converting to use unicode internally is dangerous - very dangerous - because there are many places where byte strings are assumed, and perl will fall over with it's wide bytes in the air if unicode is used.
There is, however, a compromise, and that is to modify the core so that the only charset is UTF-8, then get the stores to convert on the fly if the data on disk is encoded differently. Thus if you select UTF-8, and your store is encoded using UTF-8, everything will work seamlessly. If your store on disk is iso-8859-1, you have a choice; either set {Store}{Encoding} to iso-8859-1 and take a performance hit, or statically convert the store to use UTF-8.
I've done the necessary work on a branch (utf8), and most unit tests pass (possibly all, but my configuration is a bit odd in places)
-- CrawfordCurrie - 06 May 2015
Looks good. I ran the FoswikiSuite, have one failure:
1 failure:
StoreImplementationTests::verify_setLease_getLease_StoreImplementationTests_RcsLite
Expected null value, got 'HASH(0x9a9e188)' at /var/www/foswiki/distro/core/lib/Unit/TestCase.pm line 274.
#09;Unit::TestCase::assert_null('StoreImplementationTests=HASH(0x87dbe18)', 'HASH(0x9a9e188)') called at /var/www/foswiki/distro/core/test/unit/StoreImplementationTests.pm line 858
Are you thinking of merging this into 1.2.0 for Beta2? If we go with this, then I think we also need to include the CharsetConverterContrib as a default extension.
-- GeorgeClark - 07 May 2015
If you cherry-pick 980aebc2a4c9ca55640ed0ed849ad94ef5d5f0ae into your utf8 branch, that adds 2 TestCase topics with utf8 data. - TestCaseUtf8Rendering Looks good
- TestCaseUtf8Errors Page is corrupted if the EditRowPlugin is enabled. Appears to be a similar issue to the SubscribePlugin triggered page corruption.
- Convert all strings to unicode when they are matched by one of the $Foswiki::regex character classes, and back again afterwards (ouch)
- Convert the character classes to match the utf8 byte sequences (not worked out how to do this yet, or even if it's possible)
- Convert all internal strings to unicode (not as hard as it sounds, now that I've normalised the charset to utf8 byte strings)
- When a utf8-encoded byte string is concatenated with a unicode string, then the resulting string is marked as unicode, but the bytes contributed by the byte string are still one-character-per-byte.
-
readdirdoes not return unicode. Instead it returns inicode filenames as utf8-encoded byte strings.
decoded at the borders, e.g. everything what comes into perl is decoded. After the decode Perl knows how the characters are stored, so you don't need care, the $str1 . $str2 - will be always correct.
Ad "readdir" - same "logic" as above. Simply need decode everything what comes into perl. Filenames too. Filenames are "byte strings" (at least now - perl v5.20) - and you must know how they're encoded.
Linux is OK - it simply creates whatever filename, but here are dragons: - Windows filenames probably aren't utf8 encoded. (don't know - not tested).
- Here are operating systems - (OS X) what enforces Unicode normalisation OS X -> NFD. That's mean: the following byte string (octal)
303 241isá1 precomposed unicode character (NFC) encoded into 2 bytes. While Linux happily creates a filename with 2 bytes - on the OS X the filename will be converted to 3 bytes (NFD):141 314 201(octal) - e.g. "a" + composition sequence with the "acute". Need to say: here will be no problems when all filenames are properly decoded.
 Currently the utf8 branch is a core (and core plugins) that operate internally entirely in unicode. This was necessary in order for POSIX collation sequences to work. I've dealt with compatibility in the major extensions, but there will still be gotchas - for example, some non-core extensions may attempt to write topic/web names to STDERR/STDOUT, which will fail with a
Currently the utf8 branch is a core (and core plugins) that operate internally entirely in unicode. This was necessary in order for POSIX collation sequences to work. I've dealt with compatibility in the major extensions, but there will still be gotchas - for example, some non-core extensions may attempt to write topic/web names to STDERR/STDOUT, which will fail with a Wide byte error on unicode web/topic names. Foswiki::Func::writeDebug and friends are unicode-safe, and should be used instead.
Any code for handling special encodings on OSs will have to be handled inside the Foswiki/Store/*. Right now, in order to make rapid progress, I'm assuming the file system handles utf-8 - if you can contribute code to handle other OS's, please be my guest (check in to the utf8 branch).
Oh, and thank you for those testcases - that is marvellous, I've been waiting for a long time for someone to help with unicode.
-- CrawfordCurrie - 09 May 2015
Crawford, I've noticed that the TestCaseUtf8Errors was being incorrectly rendered on the utf8 branch. It appears that the Content-Length header is generated with a shorter length, and Firefox truncates the output. The generated header is Content-Length: 77757.
Removing that header by commenting it out in Foswiki/Request.pm, and the page renders correctly.
-- GeorgeClark - 10 May 2015
Chrome has the same issue. Page is truncated. The following patch calculates the correct length: ... Content-Length 80421
diff --git a/core/lib/Foswiki/Response.pm b/core/lib/Foswiki/Response.pm
index ccdb584..01b2638 100644
--- a/core/lib/Foswiki/Response.pm
+++ b/core/lib/Foswiki/Response.pm
@@ -369,7 +369,9 @@ Gets/Sets response body. Note: do not use this method for output, use
sub body {
my ( $this, $body ) = @_;
if ( defined $body ) {
- $this->{headers}->{'Content-Length'} = length($body);
+ use bytes;
+ my $len = bytes::length($body);
+ $this->{headers}->{'Content-Length'} = $len;
$this->{body} = $body;
}
return $this->{body};
-- GeorgeClark - 10 May 2015
Thanks George, I merged the patch.
-- CrawfordCurrie - 10 May 2015
Some errors in the utf8 branch (tested: 11742139c4a279ea377c7b5b93a3d62cb93f31e7) - The rename produces error and an long not readable perl-stack listing. The topic name is ascii-only.
During rename of topic Sandbox.QqqWww to Jomoutf an error (PlainFile: move /me/fw/sites/refcdot18000/foswiki/core/data/Sandbox/QqqWww.txt to /me/fw/sites/refcdot18000/foswiki/core/data/Jomoutf/QqqWwwXxx.txt failed: Not a directory at /me/fw/sites/refcdot18000/foswiki/core/lib/Foswiki/Store/PlainFile.pm line 1354. at /Users/clt/perl5/perlbrew/perls/perl-5.20.1/lib/site_perl/5.20.1/CGI/Carp.pm line 357. CGI::Carp::realdie("PlainFile: move /me/fw/sites/refcdot18000/foswiki/core/data/S"...) called at /Users/clt/perl5/perlbrew/perls/perl-5.20.1/lib/site_perl/5.20.1/CGI/Carp.pm line 449 CGI::Carp::die("PlainFile: move /me/fw/sites/refcdot18000/foswiki/core/data/S"...) called at /me/fw/sites/refcdot18000/foswiki/core/lib/Foswiki/Store/PlainFile.pm line 1354 Foswiki::Store::PlainFile::_moveFile("/me/fw/sites/refcdot18000/foswiki/core/data/Sandbox/QqqWww.txt", "/me/fw/sites/refcdot18000/foswiki/core/data/Jomoutf/QqqWwwXxx"...)
- YES, you was right - the encoding problem (using unicode topic names) in the redirect exists, e.g. create page, save, back-in-the-browser, save-again, after the confirmation = scrambled topic name.
- And one more minor error - but unfortunately i forgot what it was :|
Foswiki/I18N.pm see the Item13399. Here is the copy:
@@ -339,7 +339,7 @@
foreach my $tag ( available_languages() ) {
my $h = Foswiki::I18N->get_handle($tag);
my $name = eval { $h->maketext("_language_name") } or next;
- print LANGUAGE "$tag=$name\n" if $cache_open;
+ print LANGUAGE Encode::encode_utf8("$tag=$name\n") if $cache_open;
# Filter on enabled languages
next
-- JozefMojzis - 12 May 2015
For the rename error - revert one change what you made. You don't want call dirmove for the files, only for the directories.
--- refcdot18000/foswiki/PlainFileStoreContrib/lib/Foswiki/Store/PlainFile.pm 2015-05-11 00:01:48.000000000 +0200
+++ devcdot8000/foswiki/PlainFileStoreContrib/lib/Foswiki/Store/PlainFile.pm 2015-05-12 20:12:20.000000000 +0200
@@ -1344,7 +1344,7 @@
die "PlainFile: move target $to already exists" if -e $to;
_mkPathTo($to);
my $ok;
- if ( -e $from ) {
+ if ( -d $from ) {
$ok = File::Copy::Recursive::dirmove( $from, $to );
}
else {
-- JozefMojzis - 12 May 2015
Fix for the SpreadSheetPlugin PROPER function:
--- refcdot18000/foswiki/SpreadSheetPlugin/lib/Foswiki/Plugins/SpreadSheetPlugin/Calc.pm 2015-04-11 16:42:02.000000000 +0200
+++ devcdot8000/foswiki/SpreadSheetPlugin/lib/Foswiki/Plugins/SpreadSheetPlugin/Calc.pm 2015-05-12 21:34:18.000000000 +0200
@@ -314,9 +314,8 @@
PI => sub { 3.1415926535897932384 },
PRODUCT => \&_PRODUCT,
PROPER => sub { # FIXME: I18N
- my $rslt = lc( $_[0]);
- $rslt =~ s/(^|[^a-z])([a-z])/$1 . uc($2)/ge;
- return $rslt;
+ $_[0] =~ s/(\w+)/\u\L$1/g;
+ return $_[0];
},
PROPERSPACE => sub { _properSpace($_[0]) },
RAND => sub {
-- JozefMojzis - 12 May 2015
Confirmed. The patch works fine in the unit tests. Works on perl 5.8.8 too, so safe to apply.
-- GeorgeClark - 13 May 2015
Normalisation problem.
When uploading from OS X (what has ENFORCED NDF normalisation for the FILENAMES), after the Encode::decode_utf8 - the Foswiki got NFD string in for the uploaded filename
- saves the file with NFD filename
- and also uses this NFD filename for the attachment name.
- define than the Foswiki will use NFC normalised string everywhere internally.
- when reading from network just after the Encode::decode_utf8
--- refcdot/foswiki/core/lib/Foswiki/Engine.pm 2015-05-14 16:15:30.000000000 +0200
+++ devcdot/foswiki/core/lib/Foswiki/Engine.pm 2015-05-15 08:34:54.000000000 +0200
@@ -19,6 +19,7 @@
use Error qw( :try );
use Assert;
use Scalar::Util ();
+use Unicode::Normalize qw(NFC);
BEGIN {
if ( $Foswiki::cfg{UseLocale} ) {
@@ -192,12 +193,12 @@
if ( defined $value ) {
$value =~ tr/+/ /;
$value =~ s/%([0-9A-F]{2})/chr(hex($1))/gei;
- $value = Encode::decode_utf8($value);
+ $value = NFC(Encode::decode_utf8($value));
}
if ( defined $param ) {
$param =~ tr/+/ /;
$param =~ s/%([0-9A-F]{2})/chr(hex($1))/gei;
- $param = Encode::decode_utf8($param);
+ $param = NFC(Encode::decode_utf8($param));
push( @{ $params{$param} }, $value );
push( @plist, $param );
}
--- refcdot/foswiki/core/lib/Foswiki/Engine/CGI.pm 2015-05-14 16:15:30.000000000 +0200
+++ devcdot/foswiki/core/lib/Foswiki/Engine/CGI.pm 2015-05-15 08:37:44.000000000 +0200
@@ -16,6 +16,7 @@
use warnings;
use CGI;
+use Unicode::Normalize qw(NFC);
use Foswiki::Engine ();
our @ISA = ('Foswiki::Engine');
@@ -232,11 +233,11 @@
return unless $ENV{CONTENT_LENGTH};
my @plist = $this->{cgi}->multi_param();
foreach my $pname (@plist) {
- my $upname = Encode::decode_utf8($pname);
+ my $upname = NFC(Encode::decode_utf8($pname));
my @values;
if ($Foswiki::UNICODE) {
@values =
- map { Encode::decode_utf8($_) } $this->{cgi}->multi_param($pname);
+ map { NFC(Encode::decode_utf8($_)) } $this->{cgi}->multi_param($pname);
}
else {
@values = $this->{cgi}->multi_param($pname);
@@ -256,7 +257,7 @@
my %uploads;
foreach my $key ( keys %{ $this->{uploads} } ) {
my $fname = $this->{cgi}->param($key);
- my $ufname = Encode::decode_utf8($fname);
+ my $ufname = NFC(Encode::decode_utf8($fname));
$uploads{$ufname} = new Foswiki::Request::Upload(
headers => $this->{cgi}->uploadInfo($fname),
tmpname => $this->{cgi}->tmpFileName($fname),
Works for me (e.g. in the attachment table i got saved NFC) but can't test the saved filename - it is enforced to NFD. The enforcing policy in the OS X ensures the open NDF_filename and open NFC_filename are opens the same files.
How to test this.
The following script generates two files with the name characters (only differently normalised). On the OS X - it dies. On the Linux, FreeBSD you will get two files. Try upload BOTH files into some topic and check the result.
#!/usr/bin/env perl
use 5.014;
use strict;
use warnings;
use charnames qw(:full);
use Path::Tiny;
use Data::Dumper;
use utf8;
use Unicode::Normalize qw(NFD NFC);
use Encode;
use open qw(:std :utf8);
my $ch = {
c => "\N{U+0010C}", # LATIN CAPITAL LETTER C WITH CARON
a => "\N{U+000E1}", # LATIN SMALL LETTER A WITH ACUTE
r => "\N{U+00158}", # LATIN CAPITAL LETTER R WITH CARON
y => "\N{U+000FD}", # LATIN SMALL LETTER Y WITH ACUTE
};
my $str = join '', @$ch{qw(c a r y)};
my $name = {
nfc => NFC($str),
nfd => NFD($str),
};
say "$_: ", map { s/(..)/$1 /gr } unpack "H*", Encode::encode('utf8', $name->{$_}) for sort keys %$name;
say Dumper($name);
my $tmp = Path::Tiny->tempdir(DIR => ".", CLEANUP => 0);
say "Check the $tmp directory: find $tmp -type f -print | xxd";
$tmp->child($name->{nfc})->spew_utf8("this file has NFC filename [$name->{nfc}]\n");
die "$name->{nfd} exists" if $tmp->child($name->{nfd})->exists; #on the OS X dies..
$tmp->child($name->{nfd})->spew_utf8("this file has NFD filename [$name->{nfd}]\n");
Impact
When the current installations will upgrading to unicode - could have attachments what are uploaded to Linux Foswiki from the Mac computers. E.g. they have NFD encoded files (and filenames in the attachment tables). So the CharsetConverterContrib should deal with this. Maybe others impacts too.  -- JozefMojzis - 15 May 2015
Also, in the Unicode::Normalize doccu is an sentence:
-- JozefMojzis - 15 May 2015
Also, in the Unicode::Normalize doccu is an sentence:
Parameters: $string is used as a string under character semantics (see perlunicode).What's mean: needs the
feature unicode_string . This default from the 5.14 (and can use feature 'unicode_string' ) from the 5.12. But probably will NOT work with older perls. So, the unicode branch need at least 5.12 (and need modify the source to add the "use feature"), or use at least 5.14 - where this is default. Again coping with the Foswiki's "need support geriatric perls" probleme..  -- JozefMojzis - 15 May 2015
We discussed the normalisation issues on IRC, and agreed (at least for now) that we can sit on it. http://irclogs.foswiki.org/bin/irclogger_log/foswiki?date=2015-05-15,Fri&sel=13#l9
Unit tests are all working (with one reported exception) Note that there have been a large number of updates to the tests, as I discovered that many of them were not being run correctly, and there were masked failures. These are fixed on utf8 branch, but not on master, sorry
I have tested most of the core plugins, and everything seems fine.
I have not looked at the problem of running the conversion scripts on a unicode foswiki. I don't think it will be a problem, but it needs testing.
This has been a fantastic sprint - I really feel much, much happier about 1.2 now if we go out with this code.
-- CrawfordCurrie - 15 May 2015
As i told few days ago in the IRC, this is an really wonderful, marvellous, incredible, unbelievable and (don't know more words for the excellent) work. Foswiki finally and 1st times in the history has real utf8 support - and not only for topic contents but also for the programmers. (In the code the
-- JozefMojzis - 15 May 2015
We discussed the normalisation issues on IRC, and agreed (at least for now) that we can sit on it. http://irclogs.foswiki.org/bin/irclogger_log/foswiki?date=2015-05-15,Fri&sel=13#l9
Unit tests are all working (with one reported exception) Note that there have been a large number of updates to the tests, as I discovered that many of them were not being run correctly, and there were masked failures. These are fixed on utf8 branch, but not on master, sorry
I have tested most of the core plugins, and everything seems fine.
I have not looked at the problem of running the conversion scripts on a unicode foswiki. I don't think it will be a problem, but it needs testing.
This has been a fantastic sprint - I really feel much, much happier about 1.2 now if we go out with this code.
-- CrawfordCurrie - 15 May 2015
As i told few days ago in the IRC, this is an really wonderful, marvellous, incredible, unbelievable and (don't know more words for the excellent) work. Foswiki finally and 1st times in the history has real utf8 support - and not only for topic contents but also for the programmers. (In the code the \w matches word-characters) Going to pull, and will test more and more and more ... But I already got a feeling - this should be the real master, and the current should be as "preunicode" branch. THANK YOU Crawford.
-- JozefMojzis - 15 May 2015
Patch for the DIrectedGraphPlugin
--- /tmp/DirectedGraphPlugin.pm 2015-05-15 22:57:10.000000000 +0200
+++ ./DirectedGraphPlugin.pm 2015-05-15 23:04:05.000000000 +0200
@@ -573,7 +573,7 @@
# as they are include in $attr.
my $hashCode =
- md5_hex( 'DOT'
+ md5_hex( map { $Foswiki::UNICODE ? Encode::encode('utf8', $_) : $_ } 'DOT'
. $desc
. $attr
. $antialias
The md5_hex doesn't like wide characters, e.g. when we are unicode -> encode...
-- JozefMojzis - 15 May 2015
DirectedGraphPlugin is not a core plugin, and I'm not touching it - can you please raise a new task against this plugin with the above report? Ta.
-- CrawfordCurrie - 16 May 2015
CDot, one bug remains. The redirect bug after the edit,save,back,save,confirm - on the unicode topic name.
-- JozefMojzis - 15 May 2015
Huh? I was pretty sure I fixed that. Can you please describe how you caused it?
-- CrawfordCurrie - 16 May 2015
Topic with utf8 name. Edit -> Save -> back button on the browser (got again edit) -> save -> (got confirmation window) -> OK -> scrambled topic name..
-- JozefMojzis - 16 May 2015
One more bug. Probably something with Fcgi. Steps to repro:
-
cd tools -
perl lighttpd.pl - Create SomeTopic and enter one character "é"
- save
- try edit with wysiwyg
- result: OK
- CTRL-C the
lighttpd.pland start it as -
perl -f lighttpd.pl#note the -f e.g. fastcgi - go to SomeTopic
- edit with wysiwyg
- result: scarmbled.
lighttpd is invoked. OK, new bugs will be reported as usually.
-- JozefMojzis - 19 May 2015
This adds a regression in jquery.wikiwords Item13608
-- MichaelDaum - 04 Aug 2015
ItemTemplate edit


| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
DataFormSnap1.png | manage | 29 K | 21 Apr 2015 - 07:03 | MichaelDaum | |
| |
LocalSite.cfg | manage | 31 K | 21 Apr 2015 - 07:14 | JozefMojzis | my LocalSite.cfg |
| |
screenshot_63.png | manage | 57 K | 20 Apr 2015 - 23:54 | JozefMojzis | úů |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Edit | Attach | Print version | History: r56 < r55 < r54 < r53 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r56 - 04 Aug 2015, MichaelDaum
The copyright of the content on this website is held by the contributing authors, except where stated elsewhere. See Copyright Statement.  Legal Imprint Privacy Policy
Legal Imprint Privacy Policy
Legal Imprint Privacy Policy